
深度学习(Deep Learning),是机器学习的分支,是指使用多层的神经网络进行机器学习的一种手法,它学习样本数据的内在规律和表示层次,最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习中的深度指的是神经网络的层数。深度一般超过8层的神经网络叫深度学习。含多个隐层的多层学习模型是深度学习的架构。深度学习可以通过组合低层特征,形成更加抽象的高层以表示属性类别或特征,从而发现数据的分布式特征表示。
概述
编辑深度学习是一种基于人工神经网络对数据进行表征学习的算法。人工神经网络(Artificial Neural Network)是基于人工神经元(类似于生物大脑中的生物神经元)的连接单元的集合,也被称为神经网络。神经元之间的每个连接(突触)都可以将信号传输到另一个神经元。接收神经元(突触后)可以处理信号,然后发信号通知与之相连的下层神经元。神经元一般具有激活和抑制两种状态,只有激活的神经元才能向下游神经元发送信号。神经元和突触之间还存在权重,用来权衡信号的强度,权重也可以随着学习的进行而变化,这可以增加或减少其向下层发送的信号的强度。通常,神经元是分层的。不同的层可以对它们的输入执行不同种类的操作,而信号就从第一层(输入)传播到最后一层(输出),同时信号也可以多次遍历某些层之后进行输出。这样的网络通常通过示例来不断学习,进而逐步提高其能力。
深度学习的实质,是通过构建具有很多隐层的机器学习模型和利用海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。


特点
深度学习提出一种让计算机自动学习模式特征的方法。这种方法可以将特征学习融入到建立模型的过程中,使目标进行归一化。相比传统的学习方法,深度学习具有更强的学习能力,还能够减少人为设计的不完备性;深度学习的基本架构是人工神经网络,针对不同的应用目标会有不同的表达结构,目的是为了更好地提取相应领域的特征;深度学习是基于数据驱动的,它对数据的依赖性很高,数据量越大,其性能表现也越好。同时,通过调整参数,还可以进一步提升其性能上限。尽管深度学习在许多方面表现出色,但要完成这些任务,对数据量和硬件的要求也非常高,因此带来的成本也昂贵;深度学习在各个领域都有广泛应用,并且具有较好的适应性。随着神经网络层数的增加,网络的非线性表征能力也越来越强。这意味着理论上可以将其映射到几乎任何函数,因此可以应对多种复杂问题。然而,当模型设计变得极为复杂时,需要大量的人力、物力和时间来开发新的算法和模型。同时,对模型正确性的验证也变得复杂困难,导致大部分人只能使用现成的模型。
概念辨析
人工智能方法包括机器学习和其他方法,比如专家系统,其在20世纪70年代是人工智能的主流。但随着人类进入大数据时代,基于归纳的机器学习方法逐渐成了主流。
机器学习包含了特征学习和非特征学习,决策树、逻辑回归等方法是非特征学习,需要筛选并指定特征,然后建立模型。特征学习是指可以自动学习特征并进行筛选,只需输入包含所有特征的数据即可。在特征学习中又包含深度学习和浅度学习,多层的神经网络就是深度学习。深度学习与传统的机器学习之间存在着很大的不同,其中一个主要的不同点就在于深度学习通常不需要进行特征量的设计。在传统的机器学习中,通常需要根据任务来选择特征量提取的方法,并将其与机器学习算法结合起来实现所需要的机器学习任务。
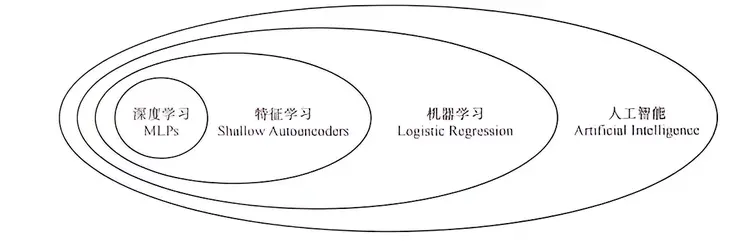
深度学习、机器学习和人工智能的关系
历史沿革
编辑1965年,数学家奥·赫·伊瓦赫年科(A.G.Ivakhnenko)和他的同事们提出了首个深度神经网络。他们开发了一种能够自动结构化模型和参数优化的方法,称为数据处理的分组方法(GMDH),并将其应用于神经网络的构建。他们的模型采用了深度前馈多层感知机的结构,每一层都通过统计学方法找到最优特征传递到后续的网络层中。1971年,他们成功训练了一个8层的深度神经网络,并在一个名为Alpha的计算机识别系统中成功地演示了网络学习过程。
1979年,第一个“卷积神经网络”(C++onvolutional Neural Networks)被福岛邦彦使用。福岛设计了具有多个池化层和卷积层的神经网络,他开发了一种名为Neocognitron的人工神经网络,该网络使用分层、多层设计,这种设计允许计算机“学习”识别视觉模式,这些网络类似于现代版本,但采用多层重复激活的强化策略进行训练。
反向传播早在1960年代初就已经衍生出来,但形式低效且不完整。直到1985年,鲁姆哈特(Rumelhart)、辛顿(Hinton)和威廉姆斯(Williams)表明,神经网络中的反向传播可以产生有趣的分布式表示,从哲学上讲,这一发现揭示了认知心理学中的问题:人类的理解是否依赖于符号逻辑(计算主义)或分布式表示(连接主义)。
反向传播的第一个真正的实际应用是通过1989年贝尔实验室的LeCun的工作实现的。他将卷积网络与反向传播相结合来对手写数字进行分类(MNIST),该系统后来被用于读取美国的大量手写支票。
1995年,支持向量机模型被进一步完善。支持向量机(SVM)从20世纪60年代就出现了,经过几十年的改进和完善,目前常用的标准模型由考特斯(Cortes)和万普尼克(Vapnik)于1993年设计,并于1995年提出。支持向量机是一个识别和映射相似数据的系统,它可以用于文本分类、手写字符识别和图像分类。用于循环神经网络的LSTM(长短期记忆)由赛普·霍克赖特(Sepp Hochreiter)和于尔根·施米德休伯(Jürgen Schmidhuber)于1997 年开发。
1999 年,当时计算机处理数据的速度开始变得更快,GPU(图形处理单元)被开发出来。通过GPU处理图片,更快的处理速度在10年内将计算速度提高了1000倍。在此期间,神经网络开始与支持向量机竞争。虽然神经网络与支持向量机相比较慢,但神经网络使用相同的数据提供了更好的结果。到2011年,GPU的速度显著提高,使得无需逐层预训练即可训练卷积神经网络成为可能。随着计算速度的提高,深度学习在效率和速度方面具有明显的优势。
2006年,加拿大多伦多大学计算机系教授辛顿(Geoffrey Hinton)在《科学》杂志上发表了《利用神经网络刻画数据维度》一文,首次提出了深度学习的概念,并探讨了应用人工神经网络刻画数据的学习模型。这标志着深度学习作为人工智能的一个分支正式提出,它本质上是一个深度神经网络和计算机深度学习模型。
2009 年,ImageNet数据集提出。斯坦福大学人工智能实验室负责人,李飞飞教授在2009年推出了一个具有超过1400万张具有人工标注的海量公开图像数据集,以供研究人员、教育工作者和学生使用。该数据集为机器学习这一数据驱动的方法提供了继续的数据原料,极大地促成了之后神经网络的兴起。
2011年,卷积神经网络AlexNet提出。2011至2012年间,亚历克斯·克里热夫斯基凭借其设计的卷积神经网络AlexNet在几项重要的国际机器和深度学习比赛中以巨大的优势战胜了以往基于浅层神经网络与传统机器学习算法的其他方法。AlexNet的成功在机器学习领域掀起了一场复杂神经网络的复兴潮。
早在2011年,Google就已经提出了利用大规模神经网络进行图像识别的技术,由于深度学习计算需要大量的计算资源和算力支持,此时传统的CPU和GPU并不能完全满足这种需求,因此NPU应运而生。2016年,Google发布了自己的TPU(Tensor Processing Unit,张量处理器)芯片,它是一种专门用于进行深度学习计算的ASIC(Application-Specific Integrated Circuit,专用集成电路)。
2014年,古德费洛(Goodfellow)创建了生成对抗性神经网络(GAN)。生成对抗性神经网络使用零和博弈论将两个相互竞争的神经网络结合起来,使其能够产生更加清晰、离散的输出。
AlphaGo是由 Google 公司 DeepMind 团队研发的围棋机器人,是第一个击败人类职业围棋选手、获得围棋世界冠军的人工智能机器人。2016年1月27日,国际顶尖期刊《Nature》封面文章报道,AlphaGo 在没有任何让子的情况下,以5:0完胜欧洲围棋冠军、职业二段选手樊麾。2016年3月,AlphaGo在韩国首尔挑战世界围棋冠军李世石九段,最终以4:1的总比分胜出。AlphaGo主要工作原理是“深度学习”,是指多层的人工神经网络和训练方法。一层神经网络会把大量矩阵数字作为输入,通过非线性激活方法取权重,再产生另一个数据集合作为输出,和生物神经大脑的工作机理一样,通过合适的矩阵数量,多层组织链接一起,形成神经网络“大脑”进行精准复杂的处理。
技术原理
编辑深度学习源自对人工神经网络(简称ANN)的研究。人工神经网络由多个人工神经元(Artificial Neuron)组成,这些神经元以一定方式连接构成网络。神经网络一般包括三层,分别为输入层、隐藏层和输出层。输入层的神经元接收输入信号(用小方块表示),隐藏层的神经元之间有连接,同时每个隐藏层神经元与输出层的神经元相连。人工神经网络中的输入和各层神经元的数量不固定,隐藏层也可以包含多个层。这种深度结构通过多层结构实现逐层特征变换,能够将原始输入转换到新的特征空间,用较少的参数来逼近复杂函数,揭示数据丰富的内在信息。
神经网络可以抽象成一个泛化型的函数,该函数由神经网络的参数构成。每个神经元都有一个权重参数W和偏置参数b,神经网络的学习就是对这些参数进行求解使其实现从输入到输出的函数功能。通过训练样本来学习神经网络的这些参数,一旦学习过程结束,这些参数即为固定值。最后给定任何一组数据,都可以用这个函数得到输出。神经网络在分类问题及回归问题上得到广泛的应用。
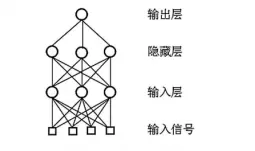
人工神经网络示例
深度神经网络是深度学习的基础,在深度学习中,“深度”是指神经网络模型的层数。一般来说,层数越多,模型就越复杂,能够处理的输入数据就越复杂。深度学习主要涉及使用多层神经网络模型来处理和分析数据。与传统的机器学习方法相比,深度学习能够自动提取数据的低级和高级特征,从而更好地拟合数据。深度神经网络包含多个隐藏层,每一层都可以采用监督学习或无监督学习进行非线性变换,实现对上一层的特征抽象。通过逐层的特征组合方式,深度神经网络将原始输入转化为浅层特征、中层特征、高层特征直至最终的任务目标。深度神经网络是基于感知机模型而提出的深层次网络结构,它通过在原始感知机模型的单层结构中加入多个隐藏层来增加深度神经网络的表达能力,此外,它的输出层可以有多个输出,可用于多分类问题和回归问题等,并且它通过增加每层之间的激活函数,使原来的线性激活函数变为非线性激活函数,进一步增加了深度神经网络的表达能力。
激活函数是深度神经网络中重要的组成部分,它起到了非常重要的作用,深度神经网络可以进行非线性学习最主要的原因就是非线性激活函数的引人,激活函数使得神经网络可以学习非线性特征,进而逼近任何非线性函数,常见的激活函数有Sigmoid,Tanh和ReLU等。损失函数是针对深度神经网络训练集定义的,它是所有样本的误差均值,也是整个深度神经网络学习的目标,即通过模型的学习使损失函数最小,从而调整模型的参数优化模型。常见的损失函数有均方差损失,对数损失和soft-max损失等。深度神经网络的网络结构是一种前馈神经网络结构,训练时经常采用反向传播(Back Propagation,BP)算法,BP算法使用损失函数的平方作为BP算法的目标函数,采用随机梯度下降方法进行优化,最终目的是使 BP 算法的目标函数最小化,所以BP算法也可以看作是求解最小化的过程。
类型
编辑无监督学习
无监督学习是指在训练过程中不使用特定任务相关的监督信息。在深度学习中,无监督学习具有十分重要的作用。例如,通过无监督学习方式训练深度信念网络、稀疏自编码器等,目前主要是为了进行预训练,以获取一个较好的初始值,然后使用有监督训练进行优化。然而,随着计算机计算能力的不断提高,人们发现,只要有足够大的数据集,直接使用有监督学习通常也能获得较好的性能。因此,在过去的几年里,无监督学习的发展并未取得太大的进展。但是,Hinton等人期望未来无监督学习能够得到更大的发展,因为人类和动物的学习在很大程度上都是无监督的,他们通过观察世界来进行学习,而不需要教师的指导。生成式学习方法指的是利用样本数据来生成与其相符的有效目标模型。一些典型的无监督学习模型包括受限波尔茨曼机(RBM)、深度置信网络(DBN)、深度自编码网络(Deep Autoencoder,DA)等。
受限波尔茨曼机
受限玻尔兹曼机是玻尔兹曼机的一种变体,区别于玻尔兹曼机,受限玻尔兹曼机可视节点和隐含节点之间存在连接,而隐含节点两两之间以及可视节点两两之间不存在连接,也就是层间全连接,层内无连接。
深度置信网络
深度置信网络(Deep Belief Network,DBN)是概率统计学、机器学习和神经网络的融合,由多个层次组成,各层之间存在关联,但各数值之间则无直接关系。该网络的主要目标是帮助系统将数据分类至不同的类别。DBN由一系列叠加的受限波尔茨曼机(RBM)和一层BP网络构成。每层RBM的输出作为上一层RBM的输入,而最后一层的BP网络则接收最后一个RBM的输出,从而计算出最终结果。DBN中的每一层RBM都形成了一个输入特征的表示空间。这些空间并不一致,存储了输入特征不同层次的信息。在训练过程中,每一层的RBM都需要单独训练,以确保输入特征在该层尽可能多地保留有用信息。DBN可直接用于处理无监督学习中未标记数据的聚类问题,也可在RBM层的堆叠结构最后加上一个多分类(softmax)层构成分类器。
监督学习
监督学习是指通过训练样本的期望输出来指导学习的一种方式。它要求样本集中的每个训练样本都要有明确的类别标签,并通过逐步缩小实际输出与期望输出之间的差别来完成网络学习。典型的有监督判别式深度学习方法包括卷积神经网络(CNN)、深度堆叠网络(DSN)、递归神经网络(Recurrent Neural Networks,RNN)等。
卷积神经网络
卷积神经网络(convolutional neural networks,CNN)是对BP神经网络的改进,与BP相同,都采用前向传播计算输出值,并通过反向传播调整权重和偏置。其与普通神经网络的不同之处在于,CNN包含一个由卷积层和子采样层(池化层)构成的特征提取器。CNN相邻层之间的神经元并非全连接,而是部分连接,某个神经元的感知区域来自于上层的部分神经元。
卷积神经网络正向传播的主要特点包括局域感知和权值共享。局域感知指的是特征图中的每个神经元仅与输入图像的局部区域连接。而权值共享则是指同一特征图中的所有神经元共享同一卷积核,即通过共享连接权值来减少神经网络需要训练的参数个数。
深度堆叠网络
深度堆叠网络由一系列串联、重叠和分层的模块组成,每个模块都有相同的结构:线性输入层、非线性隐藏层和线性输出层。底层模块的输出是高层模块的输入单元的子集。第二个模块,即直接连接到最底层模块的模块,其输入可以选择性地包含最底层模块的输出以及原始的输入特征。
递归神经网络
递归神经网络是一种具有树状阶层结构的人工神经网络,其网络节点按照连接顺序对输入信息进行递归处理,是深度学习算法之一。RNN的提出旨在处理序列数据,因此在处理文本信息等时,当前输出与之前的输出相关,因此被称为循环神经网络。RNN隐含层神经元之间具有连接,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐含层的输出。
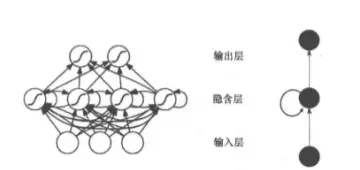
RNN层间关系
半监督学习
半监督学习是将监督学习和无监督学习相结合的学习方式,其目标是有监督的判别式模型,同时以无监督的生成式作为辅助手段,典型的半监督学习模型有积神经网络(Sum-product Network,SPN)等。
深度强化学习
深度强化学习是一种结合深度学习与强化学习的方法,从感知信息输入到动作输出的整个过程中,通过深度神经网络进行端到端的学习。这种方法使得机器人在感知信息后,能够直接输出动作,而不需要进行人工特征抽取。通过深度强化学习,机器人可以自主学习一种或多种技能,具有真正意义上的完全自主学习的潜力。DeepMind公司在Nature上发表的一篇论文“Human-level control through deep reinforcement learning”,是深度强化学习的代表性作品,该论文的发表引起了广泛关注,使得深度强化学习成为深度学习领域的前沿研究方向。
框架
编辑TensorFlow
TensorFlow是一个采用数据流图(Data Flow Graphs)的用于数值计算的开源软件库。节点(Nodes)表示数学操作,线(Edges)则表示在节点间相互联系的多维数据数组,即张量(Tensor)。它灵活的架构让用户可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU)、服务器、移动设备等。TensorFlow最初由谷歌大脑小组的研究员和工程师开发出来,用于机器学习和深度神经网络方面的研究,但该系统的通用性使其也可广泛用于其他计算领域。
PyTorch
Torch是一个科学计算框架,支持大量机器学习算法,得益于Facebook开源了大量Torch的深度学习模块和扩展,被广泛应用。其特点在于特别灵活,但由于采用了小众的编程语言Lua,增加了使用者学习及使用Torch框架的成本。PyTorch由Torch7团队开发,与Torch不同之处在于PyTorch使用Python作为开发语言,同时实现了强大的GPU加速和支持动态神经网络,这是TensorFlow所不支持的。PyTorch是GPU加速的NumPy,同时具有自动求导功能的深度神经网络。
Keras
Keras是用Python编写的高级神经网络API,可以在TensorFlow、CNTK或Theano后端上运行。它支持简单快速的原型设计,包括卷积神经网络和循环神经网络,并可以在CPU和GPU上无缝运行。Keras有助于深度学习初学者正确理解复杂的模型,旨在最大限度地减少用户操作,使模型非常易于理解。
飞桨(PaddlePaddle)
飞桨(PaddlePaddle)是由百度公司开发的开源深度学习平台,集深度学习核心框架、工具组件和服务平台为一体,同时支持动态图和静态图。它具有兼顾灵活性和高性能的开发机制、工业级的模型库、超大规模分布式训练技术、高速推理引擎以及系统化的社区服务等优势。
Jittor
2020年3月,清华大学计算机系图形实验室团队开源了Jittor,中文名计图。作为一个完全基于动态编译的深度学习框架,计图内部采用了创新的元算子和统一计算图。这些元算子和Numpy同样易于使用,可以实现比Numpy更复杂、更高效的操作。统一计算图结合了静态和动态计算图的许多优点,易于使用并且提供高性能优化。基于元算子开发的深度学习模型可以在指定的硬件设备上实现实时自动优化。在一些视觉领域中,其运算速度是PyTorch的1.4~13倍。在编程语言上,Jittor采用了灵活且易用的Python,用户可以使用它编写元算子计算的Python代码,然后Jittor将其动态编译为C++,实现高性能。
应用
编辑自然语言处理
自然语言处理(NLP)是语言学和人工智能的交叉学科,其目标是让计算机能够理解人类语言。主要涉及分词、词性标注、命名实体识别、句法分析、关键词抽取、文本分类、自动摘要以及信息检索等领域(此处所指的自然语言处理范畴仅限于文本相关)。传统的自然语言处理主要依赖语言学知识和统计学方法获取语言信息。随后,随着机器学习浅层模型(如SVM、逻辑回归等)的发展,自然语言处理取得了一定突破,但在语义消歧和语言理解方面仍有所欠缺。近年来,随着深度学习相关技术(如DNN、CNN、RNN等)的显著进展,深度学习在自然语言处理领域的应用展现出了明显优势。基于深度学习的自然语言处理在文本分类、机器翻译、智能问答、推荐系统以及聊天机器人等方面都得到了广泛应用。
计算机使用深度学习算法从文本数据和文档中收集见解和意义。这种处理自然的、人工创建的文本的能力有几个使用场景,包括自动虚拟座席和聊天机器人、自动总结文件或新闻文章、长格式文档(如电子邮件和表格)的业务情报分析和用于表示情绪(如社交媒体上的正面和负面评论)的关键短语索引。
语音识别与合成
语音相关的处理也是自然语言处理领域的一部分,目前主要包括语音合成(Text to Speech,TTS)和语音识别(Automated Speech Recognition,ASR)。语音识别是人们最为熟知且应用最广泛的领域。与自然语言处理类似,语音识别也是人工智能和其他学科的交叉领域,其涉及的领域包括模式识别、信号处理、概率论、信息论、发声原理等。随着深度学习技术的兴起,语音识别取得了显著进步,基于深度学习的语音技术不仅从实验室走向市场,还获得了谷歌、微软、百度、科大讯飞等诸多科技公司的青睐。同时,语音输入法、家用聊天机器人、医疗语音救助机、智能语音穿戴设备等具体应用场景也层出不穷。
深度学习模型可以分析人类语音,尽管说话模式、音调、语气、语言和口音不尽相同。虚拟助手(如 Amazon Alexa)和自动转录软件使用语音识别执行帮助呼叫中心座席并对呼叫进行自动分类、将临床对话实时转换为文档、为视频和会议记录添加准确的字幕以实现更广泛的内容覆盖范围等任务。
图像处理
图像领域是深度学习应用最为成熟的领域。深度学习算法在ImageNet图像识别大赛中的卓越表现,远超其他机器学习算法,以巨大优势夺魁,推动了深度学习发展的第三次浪潮。目前,基于卷积神经网络(CNN)构建的图像处理系统能够有效地减小过拟合,对大像素数图像内容有着良好的识别能力。融合GPU加速技术后,神经网络在实际中能更好地拟合训练数据,更快更准确地识别大部分的图片。综上所述,深度学习模型和图像处理技术的完美结合不仅能提高图像识别的准确率,还能在一定程度上提高运行效率,减少了一定的人力成本。
计算机视觉
计算机视觉是指计算机从图像和视频中提取信息及见解的能力。计算机可以使用深度学习技术来理解图像,就像人类一样。计算机视觉具有多种应用,包括内容审核,用于从图像和视频归档中自动删除不安全或不适当的内容;面部识别,用于识别面部和多项属性,如睁开的眼睛、眼镜以及面部毛发以及图像分类,用于识别品牌徽标、服装、安全装备和其他图像细节。
推荐引擎
应用程序可以使用深度学习方法来跟踪用户活动并开发个性化推荐。它们可以分析各种用户的行为,并帮助他们发现新产品或服务。例如,许多媒体和娱乐公司,例如 Netflix、Fox 和 Peacock,都使用深度学习来提供个性化的视频推荐。
音频和音乐处理
在音频和语音处理领域,深度学习的影响主要表现在音乐信号处理和音乐信息检索两个方面。然而,在这两个领域中,深度学习面临着一些挑战。首先,音乐音频信号并不是按照真实时间组织,而是以音乐时间组织的时间序列,它随着韵律和情感的变化而变化。测量的信号通常是多个声音的混合,这些声音在时间上是同步的,在频率上是交叠的,是短时和长时相关的混合。此外,音乐的传统、风格、作曲以及演绎等因素也会对音乐音频信号产生影响。由于音乐音频信号的高复杂度和多样性,其信号表征问题可以通过深度学习这一感知和生理驱动的技术所提供的高度抽象来解决。深度学习技术可以自动学习和提取音乐音频信号中的特征和规律,从而实现对音乐音频信号的准确分类、识别和检索。此外,深度学习技术还可以通过无监督学习等方法从大量音乐音频数据中提取有用的信息,从而实现对音乐风格的分类、音乐的生成以及对音乐表演的评价等任务。
递归神经网络(RNN)也被用于音乐处理上。在音乐处理中,使用ReLU节点代替传统的非线性逻辑回归和双曲正切函数,其产生更稀疏的梯度,使得在训练过程中不易发散,并且训练速度更快。RNN主要用于音乐的和弦自动识别任务,这类研究在音乐信息检索领域备受欢迎。RNN结构利用其强大的动态系统建模能力,通过隐层中自连接的神经元形成内部记忆,能够很好地模拟时间序列,如频谱序列或和弦进行中的和弦标注。经过充分训练后,RNN可以在给定前面时刻结束的条件下来预测下一时刻的输出。RNN可以学习基本的音乐属性,包括瞬时连续性、谐波成分和瞬时动态性等。无论音频信号含糊不清、带有噪声还是难以区分,RNN都可以有效地检测出大多数音乐的和弦序列。
优势和局限
编辑优势
深度学习提供了一种让计算机进入自动学习模式的特征方法,将特征学习融入模型建立的过程中,从而减少了人为设计特征所造成的不完备性。基于深度学习的某些机器学习应用在特定条件下已经展现出超越现有算法的识别或分类能力。
局限
在只能提供有限数据量的应用场合下,由于数据量有限,深度学习算法无法对数据的规律进行无偏差的估计。为了获得更高的精度,需要借助大数据支持。此外,深度学习中图模型的复杂性导致算法的时间复杂度急剧增加,为保证实时性,需要更高级的并行编程技术和更优质的硬件支持。因此,只有一些经济实力较强的科研机构或企业,才能够进行深度学习在前沿实用应用方面的研究和探索。
相关争议
编辑2018年1月中旬,纽约大学教授马库斯发表一篇万字长文质疑深度学习极度依赖数据、学习过程是个“黑箱”、还不能自适应规则变化等。清华大学教授马少平和马库斯认为,“深度学习存在不少问题,例如深度学习是固执己见的。”他举例说,一辆AI驱动的无人车可能在模拟环境中撞树5万次才知道这是错误行为,而悬崖上的山羊却不需要多少试错机会,改变深度学习的输出很难,它缺乏“可调试性”。另外,深度学习的过程如果是黑箱,会影响它的应用领域,例如诊断病症。“AI运算像在一个黑箱子里运行,创造者也无法说清其中的套路。”马少平认为AI虽然可能给出一个结论,但是人类如果无法知道它究竟是怎么推算出来的,就不敢采信。在制造“噪音”的情况下,AI很容易判断错误。“它无法自动排除噪音,人眼看着是熊猫,AI却会误认为是长臂猿。”马少平认为AI仍处于初级阶段,还有很多问题等待解决。
深度学习很难稳健地实现工程化。北京语言大学教授荀恩东解释,工程化意味着有“通行”的规则。例如对某一个问题的解决方法确定之后可以进行固定化。而深度学习进行问题处理时,采取类似于完成项目的方式,一个一个地解题,然而世界上有无数问题,如果很难保证机器学习系统换个新环境还能有效工作,那深度学习这项技术可能并不合适帮助AI获得通行的能力,引导和人类智能相当的强人工智能的实现。
数据集和模型是深度学习领域的两大核心要素,是其所有者的重要知识财产,具有重要的商业价值。高质量的公开数据集(例如开源数据集或正在售卖的商业数据集)是深度学习繁荣的一个重要因素。然而,由于这些数据集的公开特性,恶意用户很有可能在未经授权的情况下用其训练第三方商用模型,进而破坏数据集所有者的版权,给数据集的所有者造成巨大的损失。此外,由于公开数据集的特性,现有的经典数据保护方法,例如加密、图像水印、差分隐私等,均不能直接用于保护公开数据集的版权。加密会破坏这些数据集的可用性,恶意用户只会发布其模型而不会发布其训练细节,因此防御者无法根据图像水印判断是否存在侵权行为,差分隐私需要操纵模型的训练流程。
注释
编辑展开[a]
玻尔兹曼机(Boltzmann Machine,BM)是由 Hinton 和 Sejnowski 提出的一种随机递归神经网络,可以看作一种随机生成的 Hopfield 递归神经网络是能够通过学习数据的固有内在表示解决困难学习问题的最早的人工神经网络之一,因样本分布遵循玻尔兹曼分布而命名为BM。BM 的原理起源于统计物理学,是一种基于能量函数的建模方法,能够描述变量之间的高阶相互作用。
参考资料
编辑展开[1](日)伊本贵士. IoT最强教科书 完全版 5G时代物联网技术应用解密 人工智能(AI)的基石[M]. 北京: 中国青年出版社, 2020.03: 250.
[2]金融科技理论与应用研究小组. 金融科技知识图谱[M]. 中信出版集团股份有限公司, 2021.03: 50. (2)
[3]强彦. 人工智能算法实例集锦 Python语言[M]. 西安: 西安电子科学技术大学出版社, 2022.03: 143. (2)
[4]王艳辉, 贾利民. 智能运输信息处理技术[M]. 北京: 北京交通大学出版社, 2019.10: 196-197.
[5]沈涵飞, 刘正. Python3程序设计实例教程[M]. 北京: 机械工业出版社, 2021.02: 208. (3)
[6]赵志宏, 王学军, 王辉. Python数据分析与应用[M]. 北京: 机械工业出版社, 2022.06: 158-159.
[7]王克强. 人工智能原理及应用[M]. 天津: 天津科学技术出版社, 2021.04: 151.
[8]吴陈. 计算智能与深度学习[M]. 西安: 西安电子科学技术大学出版社, 2021.03: 224. (2)
[9](日)伊藤多一. Python深度强化学习入门 强化学习和深度学习的搜索与控制[M]. 北京: 机械工业出版社, 2022.04: 56.
[10]徐昕. 人工智能 构建适应复杂环境的智能体[M]. 上海: 上海科学技术文献出版社, 2022.02: 65.
[11]A Brief History of Deep Learning.dataversity. [2023-11-23].
[12]Deep Learning in a Nutshell: History and Training.nvidia. [2023-11-23].
[13]何赛君. 深度学习探究 以高中物理为例[M]. 杭州: 浙江科学技术出版社, 2022.03: 3-4.
[14]华尔街见闻. 谷歌TPU超算,大模型性能超英伟达,已部署数十台:图灵奖得主新作.百家号. [2023-11-27].
[15]韩组团研发NPU,大模型算力需求推动中国AI神经网络处理芯片发展.人工智能物联网. [2023-11-27].
[16]上游新闻. 柯洁解读高考“本手、妙手、俗手”作文题,网友:什么手都打不过阿尔法狗.百家号. [2023-11-27].
[17]文常保. 人工智能概论[M]. 西安: 西安电子科技大学出版社, 2020.06: 146-147.
[18]刘勇 , 李青 , 于翠波. 深度学习技术教育应用: 现状和前景[J]. 开放教育研究, 2017年, (5): 114.
[19]邸慧军. 无人驾驶车辆目标检测与运动跟踪[M]. 北京: 北京理工大学出版社, 2021.04: 22-23.
[20]Paolo Perrotta. PROGRAMMING MACHINE LEARNING FROM CODING TO DEEP LEARNING[M]. 北京: 机械工业出版社, 2021.06: 178.
[21]韩力群. 智能机器人技术丛书 机器智能与智能机器人[M]. 北京: 国防工业出版社, 2022.03: 111-112. (2)
[22]王兴梅. 基于深度学习的水下信息处理方法研究[M]. 北京: 北京航空航天大学出版社, 2021.04: 64-68.
[23]杨博雄. 深度学习理论与实践[M]. 北京: 北京邮电大学出版社, 2020.09: 174-175. (2)
[24]张雄伟. 智能语音处理[M]. 北京: 机械工业出版社, 2020.09: 71.
[25]王万森. 人工智能原理及其应用 (第 4 版)[M]. 北京: 电子工业出版社, 2018: 230.
[26]黄孝平. 当代机器深度学习方法与应用研究[M]. 成都: 电子科技大学出版社 , 2017.11: 58.
[27]孙佳. 网络安全大数据分析与实战[M]. 北京: 机械工业出版社, 2022.04: 89-90.
[28]什么是深度学习?.aws. [2023-11-22].
[29]黄孝平. 当代机器深度学习方法与应用研究[M]. 成都: 电子科技大学出版社, 2017.11: 83-84.
[30]深度学习论战 AI大神们在吵什么.新华网. [2023-11-23].
[31]江勇、夏树涛团队在深度学习的版权保护领域取得新进展.清华大学深圳国际研究生院. [2023-11-27].
该页面最新编辑时间为 2024年3月16日
百科词条作者:小小编,如若转载,请注明出处:https://glopedia.cn/59671/