
在计算机领域中,byte(字节)是计算机存储和处理数据的基本单位之一,通常由8个二进制位组成。每个二进制位只能表示0或1两种状态,因此一个字节可以表示256种不同的状态组合。在计算机中,一个字节可以存储一个英文字母、数字、标点符号等ASC++++II字符,也可以存储一个8位二进制数、一个无符号整数,或者是一些控制字符。
字节发展历史
编辑名称来源
这个词最早是由德裔美国计算机科学家维尔纳-布霍尔茨(Werner Buchholz)于 1956 年 6 月提出的。当时,布霍尔茨正在设计 IBM Stretch 计算机。他特意将 bite 重写为 byte,以避免从 word 到 bit 的变异。早期的计算机使用四位和六位字节,包括美国陆军和海军使用的计算机。
路易斯-G.-杜利(Louis G.Dooley)声称,他与朱尔斯-施瓦茨(Jules Schwartz)和迪克-比勒(Dick Beeler)在麻省理工学院林肯实验室合作开发了名为 "SAGE "的防空系统时创造了 "字节"(byte)的概念。这个术语指的是小于计算机字大小的比特组,尤其是四比特组。SAGE系统是由兰德公司、麻省理工学院和IBM共同开发的。后来,施瓦茨的编程语言JOVIAL上采用了“字节”这个术语。

开发历史
字节的概念引入
1732 年,Basile Bouchon等人发明了穿孔卡。它使用了离散位对数据进行编码,并由Joseph Marie Jacquard开发,后来被IBM 等早期计算机制造商采用。它们通常有一系列规则的孔洞,可以用特定的设备(如孔打机)进行钻孔,形成特定编码以表示不同的数据。摩尔斯电码(1844年)和早期的数字通信机器(如电传打字机和股票行情机(1870年))也使用了按位对文本进行编码。
1948年,Claude E.Shannon在他的论文《通信的数学理论》中首次使用了“位”一词:“对数底数的选择与测量信息单位的选择相对应。如果使用以 为基数的单位,则生成的单位可以称为二进制数字,或者更简单地称为位”。
1940 年代和 1950 年代开发的第一台计算机使用二进制算术来执行计算和存储数据。这些早期的计算机使用真空管来执行计算并以二进制形式存储数据。这些计算机使用二进制算术来执行计算并以二进制形式存储数据。二进制文件格式由一系列以特定模式排列的二进制数字(位)组成。每个位可以有两个值之一:0 或 1。这些值用于表示两种状态或值。
1956 年,Werner Buchholz使用 IBM Stretch Super 计算机创造了“字节”一词。他在《COMPANY CONFIDENTIAL》中提出:“串行操作的最大输入输出字节大小现在为 8 位,不包括任何错误检测和纠正位。因此,Exchange 将以 8 位字节为基础运行,任何每字节少于 8 位的输入输出单元都将剩余位留空。由此产生的间隙可以在以后通过编程进行编辑”。
字节的标准化
1963年,IBM System/360体系结构推出普及了8位字节。同时期IBM还参与了ASCII码(7位128个字符)的制定、开展了EBCDIC表(8位256个字符)的制定,作为自己公司的BCDIC标准的一个升级版本。这个标准被称为EBCDIC(Extended Binary-Coded Decimal Interchange Code)。EBCDIC是一种用于大型计算机和服务器的编码系统,它能够表示更多的字符集,包括数字、字母和其他特殊字符。
20世纪60年代和70年代,随着IBM推出了8位的字节作为标准,并在后来成为计算机行业的标准。在许多计算机科学家和工程师共同开发下,字节开始被广泛应用于表示图像、音频和视频等多媒体数据。例如:1959年,Tony Hoare发明了快速排序算法,该算法可以用于对图像数据进行排序;1952年,David A.Huffman发明的霍夫曼编码算法可以用于对图像数据进行压缩;而Robert M.Zbikowski发明的小波变换算法,可以用于对图像数据进行去噪和增强等处理。
1981年,传输控制协议(TCP)是由IETF的RFC 793定义。TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议,由互联网工程任务组(IETF)的RFC 793定义。TCP协议是在网络OSI的七层模型中的第四层——传输层工作,它的主要作用是提供一个可靠的、端对端的数据传输服务。
字节的应用及扩展
1985年,Intel公司推出了32位的386系列CPU,随后又推出了64位的Itanium系列CPU。在21世纪初,AMD公司推出了64位的Opteron系列CPU,而Apple公司也在Mac OS X 10.6 Snow Leopard中引入了64位的支持。
随着计算机系统变得越来越先进,字节被用来指定各种计算机存储格式的容量,包括光盘只读存储器(CD-ROM)、固态硬盘(SSD)模块、光盘、闪存、氦气硬盘驱动器(HHDD)等。
字节定义
编辑字节(byte)是计算机信息技术用于计量存储容量的一种计量单位,也表示一些计算机编程语言中的数据类型和语言字符。byte是从0-255的无符号类型,所以不能表示负数。
单位及换算
编辑单位
B与bit
数据存储是以“字节”(byte)为单位,数据传输大多是以“位”(bit,又名“比特”)为单位,一个位就代表一个0或1(即二进制),每8个位(bit,简写为b)组成一个字节(byte,简写为B),是最小一级的信息单位。
字(Word)
在计算机中,一串数码作为一个整体来处理或运算的,称为一个计算机字,简称字。字通常分为若干个字节(每个字节一般是8位)。在存储器中,通常每个单元存储一个字。因此每个字都是可以寻址的。字的长度用位数来表示。
字长
计算机的每个字所包含的位数称为字长,计算的字长是指它一次可处理的二进制数字的数目。一般的大型计算机的字长为32-64位,小型计算机为12-32位,而微型计算机为4-16位。字长是衡量计算机性能的一个重要因素。
单位换算
单位换算
| 单位 | 换算为byte |
| 字节(byte) | 1字节(byte)=8位(bit) |
| KB( Kilobyte,千字节) | 1KB=1024B |
| MB( Megabyte,兆字节) | 1MB=1024KB |
| GB( Gigabyte,吉字节,千兆) | 1GB=1024MB |
| TB( Trillionbyte,万亿字节,太字节) | 1TB=1024GB |
| PB( Petabyte,千万亿字节,拍字节) | 1PB=1024TB |
| EB( Exabyte,百亿亿字节,艾字节) | 1EB=1024PB |
| ZB(Zettabyte,十万亿亿字节,泽字节) | 1ZB=1024EB |
| YB( Yottabyte,一亿亿亿字节,尧字节) | 1YB=1024ZB |
| BB( Brontobyte,千亿亿亿字节) | 1BB=1024YB |
字节文件
编辑字节文件,通常指由一系列字节(byte)组成的二进制文件。字节是计算机中用于计量数据量的基本单位,一个字节等于8位。字节文件可以包含任何类型的数据,包括文本、图像、音频和视频等。在Java中,有一种被称为字节码的特定类型的字节文件,这是一种中间码,由一系列操作代码/数据对组成,旨在由Java虚拟机(JVM)执行。字节文件在多种领域有广泛应用,如Java虚拟机中的.class文件、Python解释器中的.pyc文件、Lua解释器中的.luac文件等。
区别与共性
| 名称 | 共性 | 区别 |
| 文本文件 | 它们都是以二进制形式存储在计算机中、可以是文件系统中的文件类型在计算机文件系统中创建、读取和写入、由不同的字节组成的 | 它是以顺序方式存储数据的,其逻辑结构属于流式文件。文本文件通常使用ASCII码方式进行存储,英文、数字等字符存储的是ASCII码,而汉字存储的是机内码。常见的字节文件扩展名包括:.txt、.doc、.pdf等 |
| 二进制文件 | 二进制文件是由0和1组成的数据文件,这是计算机数据在物理存储上的表现形式。与文本文件不同,二进制文件包含了特殊的格式和计算机代码,通常用于存储图形文件及计算机程序等数据。不同类型的二进制文件具有各自的编码规则和结构,确保了它们能够被相应的软件正确地解释和处理。常见的二进制文件扩展名包括:.bin、.dat、.exe、.jpg等 | |
| 字节文件 | 字节文件通常指由一系列字节(byte)组成的二进制文件。字节是计算机中用于计量数据量的基本单位,一个字节等于8位。字节文件可以包含任何类型的数据,包括文本、图像、音频和视频等。常见的字节文件扩展名包括:.com、.bat等 |
字节编码方式
编辑字节的编码方式主要指的是将字符转换为字节表示的方法,以便在计算机中进行存储和处理。有一些特定的编码方式,如 EBCDIC(扩展二进制编码十进制交换码)等,多在早期的计算机系统和特定领域中使用。
ASCII 编码
概述:ASCII(American Standard Code for Information Interchange)是最早的字符编码标准,使用 7 位二进制表示 128 个字符,包括英文字母、数字、标点符号和一些控制字符。
优势:ASCII码利用了计算机底层的二进制编码系统,每个字符都分配了一个唯一的二进制编码,使得计算机可以方便地识别和处理文本。且ASCII码中,26个字母的代码是连续的,大写字母和小写字母仅通过一位的差异即可相互转换。通过扩展ASCII,可以表示更多的特殊符号、外来语字母和图形符号。
缺陷:无法表示中文等非西欧语言。同时,ASCII只能显示基本的拉丁字符,不能很好地支持其他语言字符集,如汉字、日语和俄语等。为了解决这些问题,后来发展出了Unicode编码。
应用场景:在处理文本数据时,可以使用ASCII编码来表示每个字符、电子邮件通常使用ASCII编码来传输文本消息、C、C++、Java等编程语言中的字符串常量和字符变量也是用ASCII码表示。
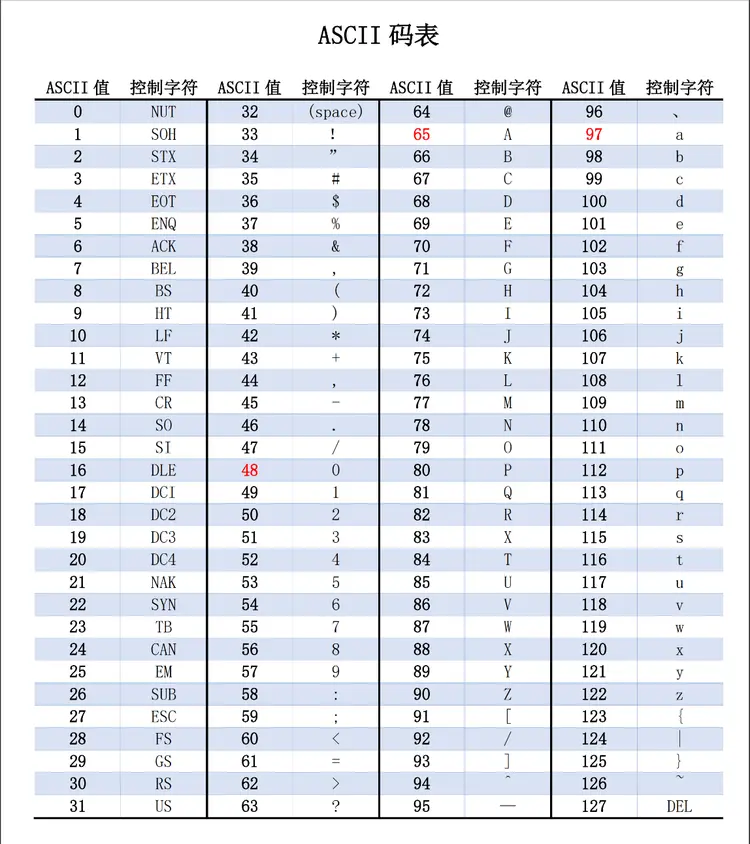
ASCII 编码
Unicode 编码
概述:Unicode中文又称万国码、国际码,是计算机科学领域的一项业界标准。它对世界上大部分的文字系统进行了整理和编码,使得电脑可以用更为简单的方式来呈现和处理文字。Unicode字符集的编码范围是0x0000 - 0x10FFFF,可以容纳一百多万个字符,每个字符都有一个二进制数值和它对应。例如,汉字“中”的码点是0x4E2D,大写字母A的码点是0x41。
优势:Unicode是国际标准字符集,对世界上大部分的文字系统进行了整理和编码。Unicode字符集中的每个字符都有一个二进制数值(也称为码点)与之对应。
缺陷:比ASCII等其他编码方式需要更多的存储空间、由于Unicode需要对每个字符进行转换和处理,因此在处理大量文本的速度比其他编码方式慢。
应用场景:跨语言、跨平台文本处理、Unicode编码可以用于各种数据库中,以支持多种语言的存储和检索。如MySQL、Oracle等数据库、网络传输中,Unicode编码可以用于实现多语言之间的数据传输和交换。如XML,,Java,LDAP, CORBA 3.0, WML等、编程语言处理。
部分Unicode 编码
ISO-8859 系列编码
概述:ISO-8859系列是由国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准。其中,ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF。在0x00-0x7F之间编码与ASCII完全一致;而在0x80-0x9F之间主要是控制字符;0xA0-0xFF之间的编码则是文字符号。此字符集主要支持部分于欧洲使用的语言。
优势:ISO-8859系列编码的优势主要体现在其兼容性和表示特定字符集的能力。该系列编码与ASCII编码兼容,这意味着所有低位都未使用。此外,ISO-8859系列编码可以表示127到255范围内的各种字母表。其中的ISO-8859-1编码独特的编码顺序为支持欧洲等地的语言提供了便利。
缺陷:ISO-8859系列编码的缺陷主要体现在其字符集范围有限,无法表示所有语言的字符。它只能容纳128个以下的符号组成的语言,或者一次不能显示一个以上的符号系列。例如,中文汉字就无法用ISO-8859系列编码完全表示,如果将UTF-8或者GBK编码格式的中文字符转成"iso-8859-1"编码格式,会变成乱码。随着UTF的兴起,ISO-8859编码已不再被广泛使用。
应用场景:在网络传输中,如果接收方的字符集与发送方不同,那么可以使用ISO-8859系列编码进行转换、一些老旧的网页或者部分http响应信息中的header部分,默认是"iso-8859-1"的编码、需要处理的数据包含部分欧洲语言可以使用到这种编码。
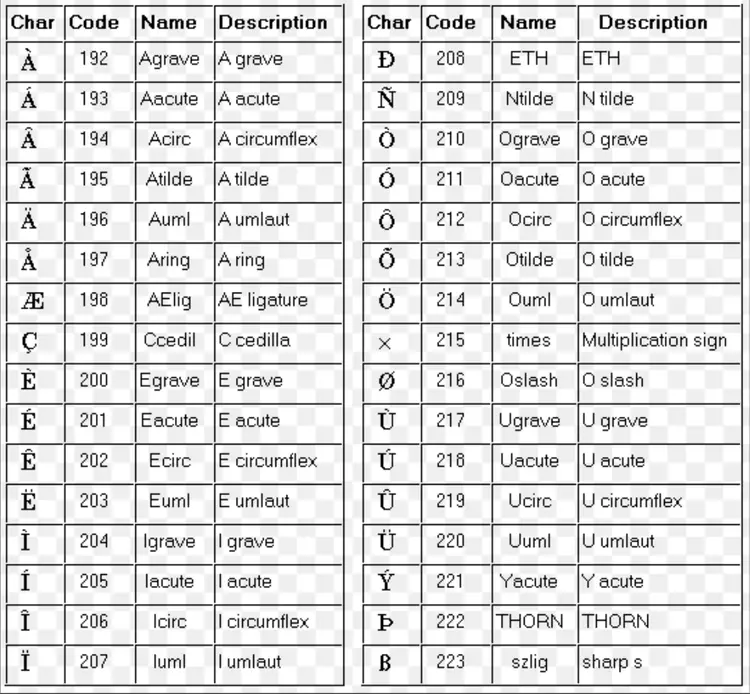
ISO-8859-1编码
字节交换
编辑字节交换(byte swapping)是指将多字节数据类型(如整数、浮点数)的字节顺序进行调换的操作。在计算机系统中,存在着不同的字节序,常见的有大端字节序(Big-endian)和小端字节序(Little-endian)两种。大端字节序是指将高位字节存储在低地址,低位字节存储在高地址的方式。而小端字节序则是将低位字节存储在低地址,高位字节存储在高地址的方式。
字节交换通常涉及到多字节数据的转换,其目的是在不同字节序之间进行转换或者确保多字节数据在特定字节序的系统上得到正确解释。例如,在网络通信中,为了确保不同系统之间的数据正确传输,需要进行字节交换。
字节与位的区别
编辑两者都是计算机内存单元的类型,但它们代表不同的大小和测量计算机数据的方法。这两个单元之间的最大区别是尺寸。位是计算机内存的最小单位,而字节由几个位组成。
bit和byte的差异
| - | Bit | byte |
| 定义 | bit 是计算机中最小的数据单位,表示一个二进制位,即 0 或 1 | byte 是计算机中常用的数据单位,由 8 个 bit 组成,可以表示更大范围的数据 |
| 大小 | bit 的大小是非常小的,仅有两种可能的状态之一:0 或 1 | byte 的大小是 bit 的 8 倍,可以表示 256种不同的状态组合 |
| 应用 | bit 主要用于表示数据的最小单位,例如位运算、数据压缩和加密等领域 | byte 用于更常见的数据表示和存储,如字符、整数、图像、音频和视频等 |
| 表示能力 | 它无法直接表示较大范围的数据 | 可以表示更复杂和更大范围的数据,如整数、字符集编码等 |
| 计量单位 | bit 则常用于衡量网络带宽和传输速度 | 在计量存储容量时,通常使用 byte 和其衍生单位 |
应用领域
编辑| 应用领域 | 介绍 | 展示 |
| 存储和传输数据 | 字节是计算机存储和传输数据的基本单位。文件和数据库系统以字节为单位读取、写入和操作数据,硬盘和闪存等存储介质以字节为粒度进行数据存储和访问。在网络通信中,数据通过字节的形式进行传输 |  存储介质--硬盘 |
| 字符编码和文本处理 | 对于文本数据,字节被用来表示字符。通过字符编码方案(如ASCII、Unicode和UTF-8等),字符被转换为相应的字节序列以实现存储和处理。字节的处理包括文本输入输出、字符串操作、字符集转换等 | 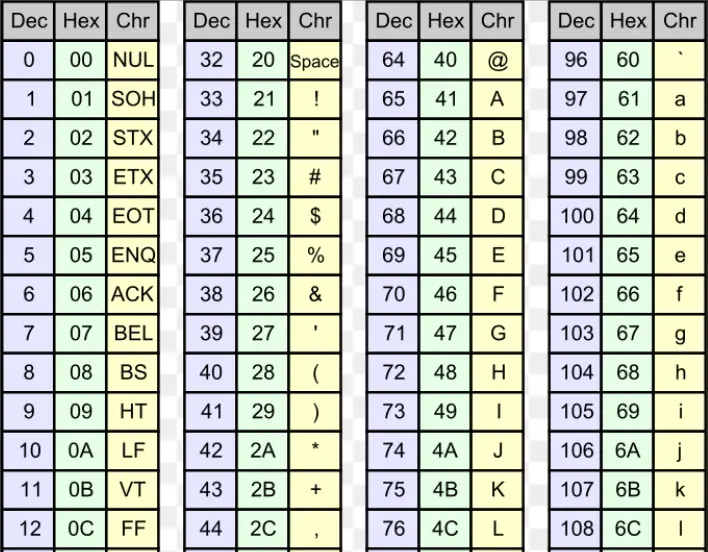 ASCLL表 |
| 图像和图形处理 | 字节的组织方式用于存储和处理图像和图形数据。图像文件以字节的形式存储像素数据,字节可以表示像素颜色、透明度和其他图像属性。在图像处理中,字节用于进行像素级操作、图像编解码、图像特征提取等 |  图形处理 |
| 音频和视频编解码 | 字节用于表示和处理音频和视频数据。音频和视频文件以字节形式存储采样和帧数据,字节被解码为音频流或视频帧,进行播放、录制、压缩和解压缩等操作 | 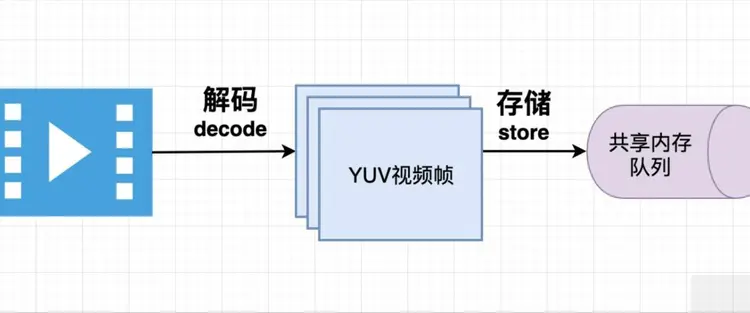 视频编解码 |
| 网络和通信协议 | 字节被广泛用于构建和解析网络和通信协议。字节序列用于定义消息的格式和结构,在传输过程中进行数据包装和解包装,用于实现数据传输的可靠性、实时性、安全性等 | 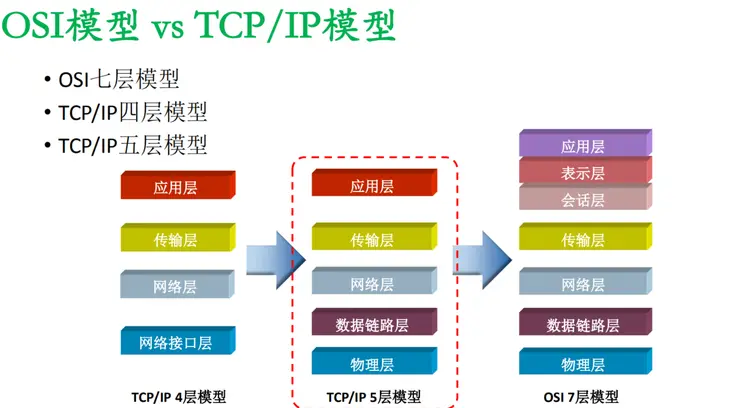 OSI模型 |
| 编程和数据结构 | 在编程中,字节被用于表示内存中的数据。字节作为最小的可寻址单元,被用于构建数据结构、定义变量和实现算法等。字节处理可以处理位操作、字节对齐、序列化和反序列化等任务 | 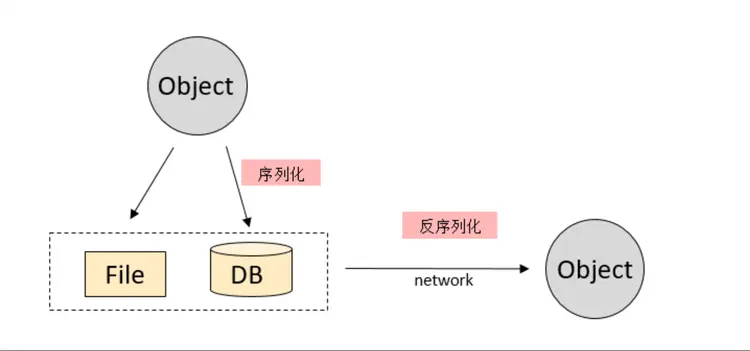 JAVA反序列化 |
百科词条作者:小小编,如若转载,请注明出处:https://glopedia.cn/8709/