
MNIST数据库简介
编辑MNIST数据库是一个大型手写数字模式数据库,MNIST是改良国家标准与技术研究院的英文缩写,英文全称为 Modified National Institute of Standards and Technology。该数据库是美国国家标准与技术研究所提出的标准,旨在使用主要基于神经网络的机器学习来校准和基准化图像识别方法。该数据由预先准备的示例图像组成,系统在此基础上进行训练和测试。MNIST数据库是通过重新设计原始 NIST 20x20 像素黑白样本集而创建的。 NIST 数据库的创建者反过来使用了美国人口普查局的一组样本,其中添加了美国大学生编写的测试样本。 NIST 集中的样本经过归一化、平滑处理并转换为 28x28 像素灰度图像。


MNIST数据库包含 60,000 张用于训练的图像和 10,000 张用于测试的图像。一半的训练和测试样本取自 NIST 训练集,另一半取自 NIST 测试集。
结果质量和方法的发展
编辑一些论文报告了基于多个神经网络集合的系统的高性能;MNIST数据库的数字识别质量与人类水平相当,而对于其他识别任务,特别是路标,甚至是人类水平的两倍。
创建者的原始网页指出,在不进行预处理的情况下,使用简单线性分类器的误差为12%。
2004年,使用三层罗森布拉特感知器的LIRA系统的误差率为0.42%。
对使用随机变形的MNIST训练进行了研究。引入了仿射或弹性变换作为失真。有时,这类系统会取得不错的成绩,特别是有出版物称其误差率为0.39%。
2011年,利用神经网络实现了0.27%的误差率。2013年,有出版物称利用神经网络正则化实现了0.21%的误差率。
后来,单卷积神经网络的应用将质量提高到了0.31%的误差水平。单卷积神经网络的最佳结果是经过74个历元训练后获得的系统,误差率为0.27%。然而,五个卷积神经网络的集合误差率为0.21%。2018年,研究人员使用随机多模型深度学习,报告的错误率为0.18%,比之前的最佳结果有所提高:一种新的集合、深度学习分类方法。
系统比较
编辑下表收集了不同图像分类系统中机器学习结果的示例:
| 类型 | 结构 | 缺失 | 预处理 | 错误 |
|---|---|---|---|---|
| 线性分类器 | 单级感知器 | 无 | 否 | 12 |
| 线性分类器 | 成对线性分类器 | 否 | 对齐 | 7.6 |
| K近邻法 | 具有非线性变形的K-NN方法 | 无 | 可移动边缘 | 0.52 |
| 梯度提升 | 基于哈氏性状的残差处理 | 否 | 哈尔符号 | 0.87 |
| 非线性分类器 | 40PCA + 二次分类器 | 否 | 否 | 3.3 |
| 参考向量法 | 虚拟支持向量系统,deg-9 poly,2像素抖动 | 否 | 对齐 | 0.56 |
| 神经网络 | 2级网络 784-800-10 | 无 | 否 | 1.6 |
| 神经网络 | 2级网络 784-800-10 | 弹性变形 | 无 | 0.7 |
| 深度神经网络 | 6级网络 784-2500-2000-2000-1500-1000-500-10 | 弹性变形 | 无 | 0.35 |
| 融合神经网络 | 6级网络 784-40-80-500-1000-2000-10 | 否 | 扩展训练数据 | 0.31 |
| 卷积神经网络 | 6级网络 784-50-100-500-1000-10-10-10 | 否 | 扩展训练数据 | 0.27 |
| 融合神经网络 | 35个卷积神经网络的集合,1-20-P-40-P-150-10 | 弹性变形 | 归一化 | 0.23 |
| 融合神经网络 | 5个卷积神经网络的集合,6级 784-50-100-500-1000-10-10-10 | 否 | 扩展训练数据 | 0.21 |
| 随机多模型深度学习 | 30个随机深度学习模型 | 无 | 否 | 0.18 |
MNIST数据训练样本
编辑该样本使用 Python 创建神经网络,需要用到的主要库有:TensorFlow、numpy、matplotlib.pyplot ,每一个代码块 = Google Colab 中的一个代码块。
连接数据库
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow и tf.keras import tensorflow as tf from tensorflow import keras # Вспомогательные библиотеки import numpy as np import matplotlib.pyplot as plt print(tf.__version__)
MNIST数据
<spanclass="n">d_mnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = d_mnist.load_data()
加载数据集返回四个 NumPy 数组:
train_images 和 train_labels 数组是训练集,即训练模型的数据。该模型在测试集(即 test_images 和 test_labels 数组)上进行测试。图像是 28x28 NumPy 数组,其中像素值范围从 0 到 255。标签是从 0 到 9 的整数数组。
class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
数据预处理
plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False) plt.show()
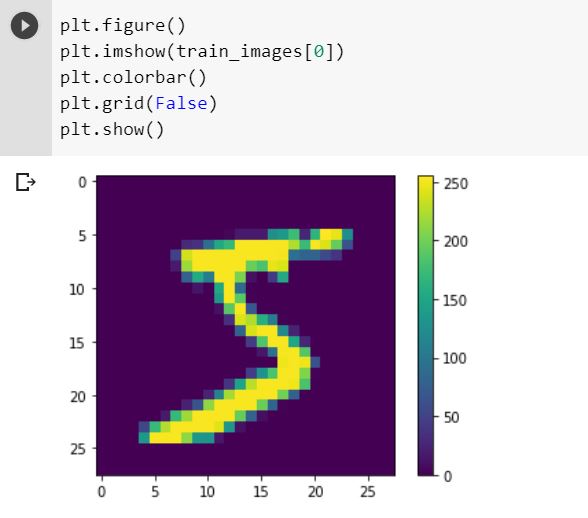
在将这些值输入神经网络之前,我们将它们缩放到 0 到 1 的范围。为此,我们将这些值除以 255。重要的是训练集和测试集的预处理相同:
train_images = train_images / 255.0 test_images = test_images / 255.0
为了确保数据格式正确并且我们准备好构建和训练神经网络,我们将显示训练集中的前 25 张图像,并在它们下面显示它们的类名称。
plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]]) plt.show()
神经网络架构和训练
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=10)
该网络的第一层 `tf.keras.layers.Flatten` 将图像格式从二维数组(28 x 28 像素)转换为一维数组(28 * 28 = 784 像素)。该层从图像中提取像素行并将它们排列成一行。该层没有训练参数;它仅重新格式化数据。
分解像素后,神经网络包含两层 `tf.keras.layers.Dense`。这些是完全连接的神经层。第一个 Dense 层由 128 个节点(或神经元)组成。第二个(也是最后一个)10 节点 softmax 层返回一个由 10 个概率分数组成的数组,总和为 1。每个节点都包含一个分数,指示图像属于 10 个类别之一的概率。

准确度 - 成功预测的百分比 损失 - 错误的百分比
在训练过程中,神经网络经历了 10 个时期 - 10 个训练周期
关注第一个时代的指标,最后一个时代的指标——第十个时代
预测
predictions = model.predict(test_images) def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array[i], true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if <spanclass="n">predicted_label == true_label: color = 'green' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('green') # Отображаем первые X тестовых изображений, их предсказанную и настоящую метки. # Корректные предсказания окрашиваем в синий цвет, ошибочные в красный. num_rows = 15 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, test_labels) plt.show()
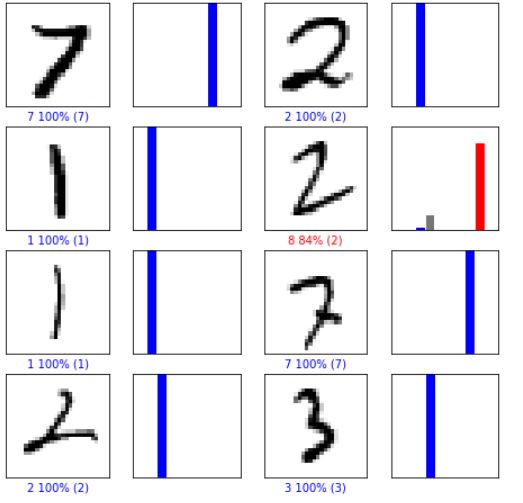
网络响应如下所示:xy% (z) ||| x - 网络响应,y% - 成功预测的百分比,(z) - 正确答案
参考资料
编辑https://st.anosov.ru/
https://www.tensorflow.org/
百科词条作者:0059,如若转载,请注明出处:https://glopedia.cn/373117/